Chendi Xue
I am linux software engineer, currently working on Spark, Arrow, Kubernetes, Ceph, c/c++, and etc.
0 Results
BLOG
Weekly Plan
| Monday | Tuesday | Wednesday | Thursday | Friday | Saturday | Sunday |
| Workday | Workday | Workday | Workday | Workday | Playday | Playday |
| Not Started | Not Started | Not started | Not started | Not started | Not started | Not started |
11 Nov 2019»
I prefered to write codes inside vim, since I can directly compile them in the same nodes, and it is free. And this blog is my Must Have when using VIM as a cpp IDE.
28 Oct 2019»
A very nice guide of setting up IKEv2 VPN server on EC2 by using strongswan(ipsec)
20 Aug 2019»
Enable Apache Arrow with HDFS and Parquet support, and continually implement a new java interface for loading parquet from hdfs.
12 Jul 2019»
Step by steps to install a tpcds kit and then prepare tpcds data.
12 Jul 2019»
Installation and evaluation of Apache Arrow and Gandiva.
11 Jul 2019»
Talk about what is WholeStageCodegen and how it worked in spark.
16 Apr 2019»
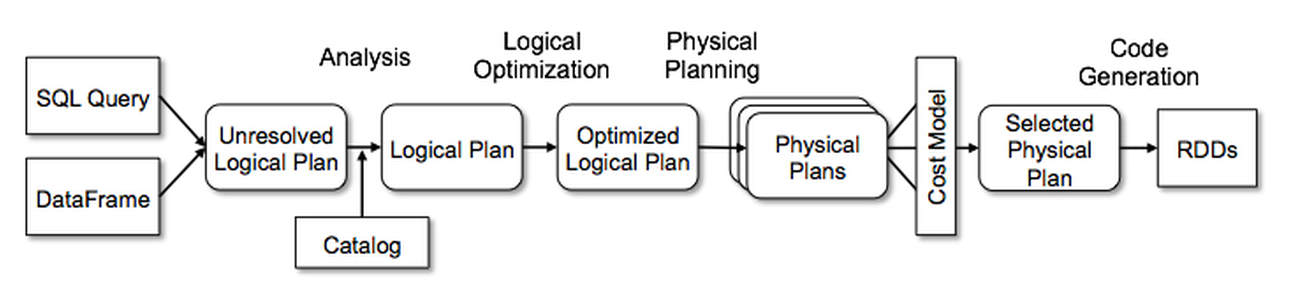
DataFrame vectorized/columnar based data format processing and row based data processing deep dive will be covered in this blog.
16 Apr 2019»
Spark is using 3.0.0(master of Apr 2019), Hadoop is using 3.2.0(claimed to be supported in spark pom.xml)
16 Apr 2019»
TensorFlowOnSpark installation and verification step by step.
16 Apr 2019»
Apache Arrow is a standardized language-independent columnar memory format platform, implemented in c++ and providing interfaces in Python, java, etc. Aim of Apache Arrow is to provide a unified data structure for different projects and different process memeory space.
15 Apr 2019»
What is Spark Shuffle and spill, why there are two category on spark UI and how are they differed? Also how to understand why system shuffled that much data or spilled that much data to my spark.local.dir? This post tries to explain all above questions.
07 Dec 2018»
PMDK is super cool, if you missed the introduction, please go to PMDK Notes 0: what it is and quick examples to have a ramp up. For this blog, three benmark codes of using C, C++ and Java PMDK interface will be demonstrated to meet different applications.
19 Oct 2018»
S3A Committer is a brand new feature in Hadoop 3.1.1, it helped to eliminated a rename operation which is a disaster to s3a performance. And I will cover how to enable S3A Committer and how to verify if S3A Committer is working and performance here.
18 Oct 2018»
I will cover how to deploy spark on kubernetes and how to run spark examples including simplest example like calculating pi, examples required input/output through HDFS and examples with Hive.
17 Oct 2018»
I met no credential provider issue after upgrading my hadoop to 3.1.1 with hive 3.1.0, since it took quite a while to find a solution, hope others may benefit from my findings
11 Oct 2018»
This is a blog to keep good java online-doc references, and may add a original one after.
10 Oct 2018»
I am always afraid of getting rusty of coding basics, data structures and algorithm. Hope this cheet sheet would help to refresh every time I needed.
10 Oct 2018»
In this series, I will continuely add some hard problem I tried on leetcode, update weekly.
10 Oct 2018»
PMDK is super cool, if you missed the introduction, please go to PMDK Notes 0: what it is and quick examples to have a ramp up. For this blog, I wrote down all my steps to build up a PMDK with its c++ api and java api in my Centos 7.3 system.
10 Oct 2018»
PMDK is a super cool open source library developed and owned by intel. This lib is used to help users to implement applications on persistent memory just like using normal memory. Which is to say, basically, when we want to manage memory, we allocate a chunk, and use pointers to indicate where data is to build a logical image and do read and write, and that is exactly how to use persistent memory by this PMDK lib. There is a new pointer, persistent_ptr, and it just can be used like a char*, super cool!