What is Apache Arrow High level Intro
Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. It also provides computational libraries and zero-copy streaming messaging and interprocess communication. Languages currently supported include C, C++, C#, Go, Java, JavaScript, MATLAB, Python, R, Ruby, and Rust.
Why we need Apache Arrow:
Apache Arrow simplifies data convertion, from “N to N” to “N to 1”.
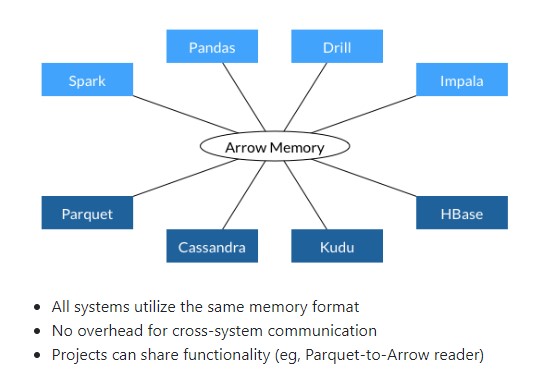
Apache Arrow provides a native memory pool for various projects to access, by which way, data is no longer need to be serialized then deserialized to copy from one kind of object to another kind of object, for example, from on-heap object to buffer or on-heap object to python object.
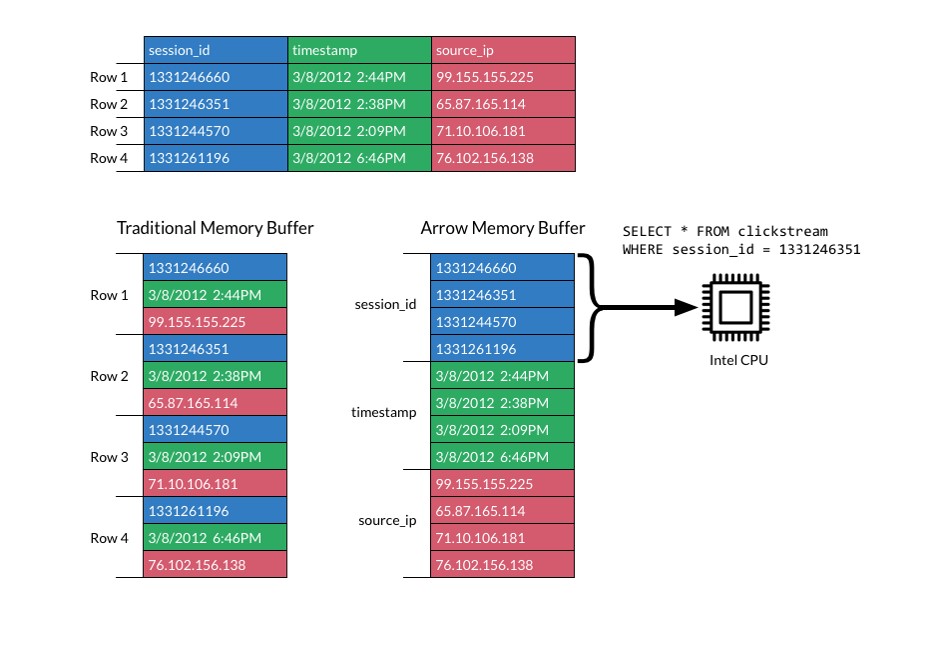
Apache Arrow provides a columnar layout allows applications to avoid unnecessary IO and accelerate analytical processing performance on modern CPUs and GPUs.
Apache Arrow Internal
Apache Arrow is implemented by c++ and based on memory. I think that is root reason of why it is capable of providing high proficiency to compare with other project of using jvm heap memory. Apache Arrow Memory Pool Implementation ![]()
The second main reason of the efficiency is because of the columar layout design, it is implemented by using one “null bitmap” + one “offset buffer” + one “value array” to describe all kinds of base one dimentional data structure, such as array.
Implementation of a List (one dimentional) in Apache Arrow.
The Null Bitmap: indicates which slot in offset buffer should be NULL instead of empty. Check the difference between slot 1 -> NULL and slot 3 -> [].
The Offset Buffer: indicates the start index and next_start index of each String mapping as a flat Buffer. see first two int32 in Offset Buffer, which is 0 and 3, mapping to the values array, it ranges “joe”.
The values Array: a flat buffer of data. Notice: instead of using “struct”, real data is putting together in Arrow, easy to copy with zero serialization>
![]()
Implementation of two dimentional data – Struct<List, Int32>
A two dimentional struct in Arrow is implemented by 1 * “parent one dimentional struct” + n * “child one dimentional struct”.
An example here is a Struct<List
And the parent only uses one Null Bitmap to indicates if there is Null inside this table.
![]()
Apache Arrow RecordBatch
RecordBatch is quite important data type in Apache Arrow, it is mostly used in Arrow RPC. And RecordBatch is also a two-dimentional data. An example is shown as below, I believe it is easy to understand the structure now.
![]()
Apache Arrow Library
Let’s then take a look of the rest of library Apache Arrow provides. Based on one-dimentional datatype and two-dimentional datatype, Arrow is capable of providing more complex data type for different use cases. Inside its python/java lib, it provides io interface such as file and stream.
![]()
Modules
Besides Apache Arrow core, it provides two important modules: Plasma(For IPC object storage based on shared memory) and Flight(RPC and Messaging framework), both is worth checking but I did’t have a chance to use any of them, skip here.
Use case and verification
Most spoken use case by using Apache Arrow is how it helped improving pyspark performance by change oroginal DataFrame to Pandas DataFrame or defining original python udf to pandas_udf. Either way is helped to indicate the memory layout and cpu to process data by columnar.
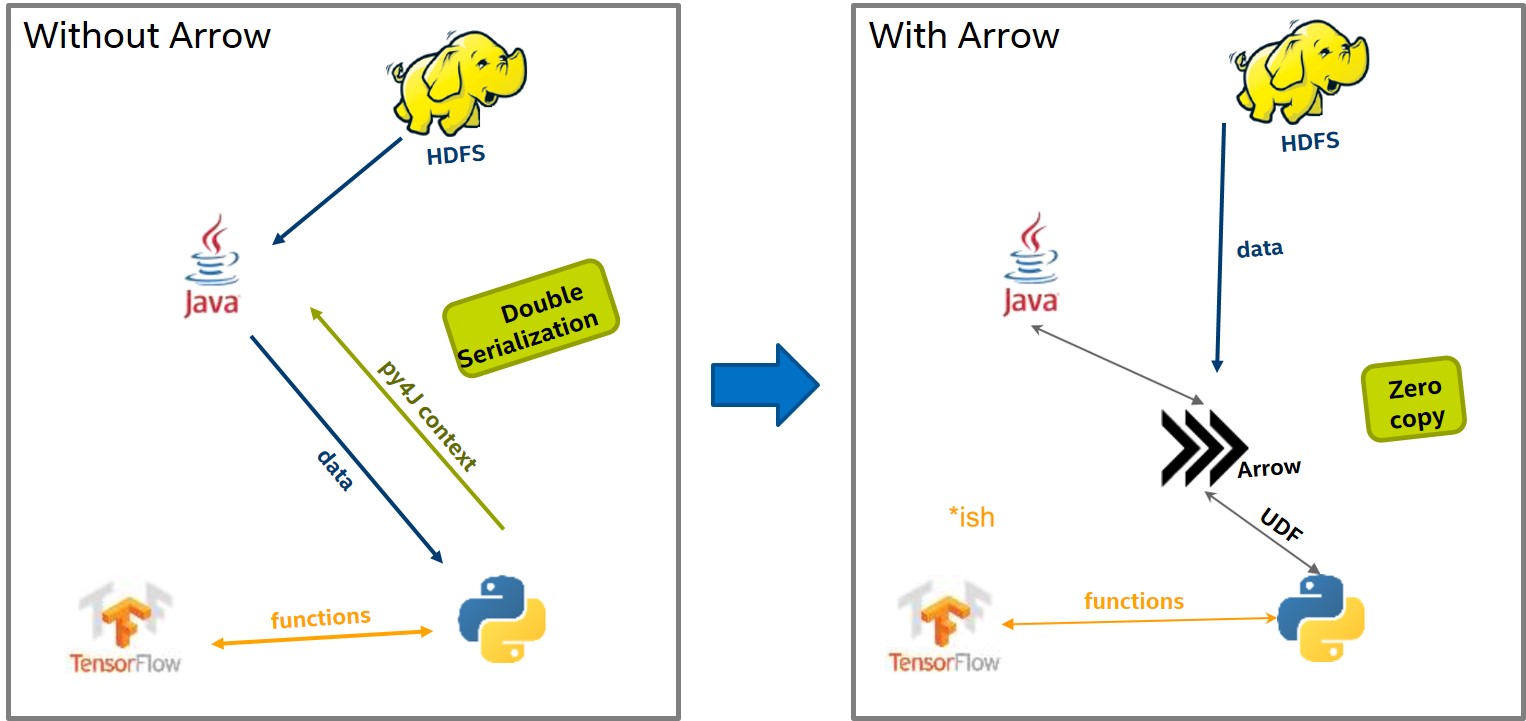
Check below pic, original data sharing between spark scala(JVM) and pyspark used pickle. It works while the efficiency is low. And may need double serialization(SourceData to python, then result back to JVM)
When changed to Arrow, data is stored in off-heap memory(No need to transfer between JVM and python, and data is using columnar structure, CPU may do some optimization process to columnar data.)
![]()
Only publicated data of testing how Apache Arrow helped pyspark was shared 2016 by DataBricks. Check its link here: Introduce vectorized udfs for pyspark.
So, I did a test by my own cluster to check if the conclusion is still the same. I also used plus_one function to verify the efficiency of different kind of python functions: compared python expression vs python udf vs pandas udf.
The test set is a table contains two columes: word and its count. The test is to plus one to the count, change from 1 to 2.
Data set is 155G, maps to 1520 partitions, each partiton is 100MB data. Only used 1 physical node to run spark with 20 executors * 4 cores. Benchmark Script Codes
![]()
Performance shows pandas_udf performance 2.62x better than python udf, aligns the conclusion from Databricks 2016 publication.
To be Expected
Databricks is now working on a Spark JIRA to Use Apache Arrow to optimize Data Exchange between Spark and DL/AI frameworks
Ideas includes things below:
support DL/AI data source load into spark as DataFrame more natively
Example code:
df = spark.read.format("images").load("s3://xxx/imagenet")
df = spark.read.format("tfrecords").load("wasb://xxx/training")
Summarize
It is promising of using Apache Arrow to do optimization, besides spark case, it is also well explored in project like Kuda, etc.