What does spark shuffle do?
Shuffling is a term to describe the procedure between map task and reduce task. And when we say shuffling, it refers to data shuffling.
What data need to be shuffled?
Let’s take an example. Say states in US need to make a ranking of the GDP of each neighborhood. Imagine the final result shall be something like Manhattan, xxx billion; Beverly Hills, xxx billion, etc.
And since there are enormous amount of neighborhood inside US, we are using terasort algorithm to do the ranking.
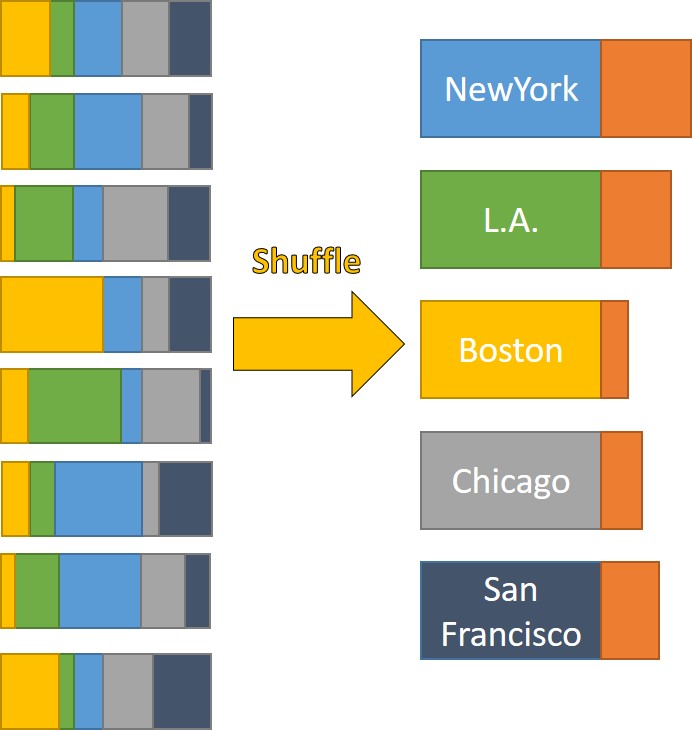
- Each map task input some data from HDFS, and check which city it belongs to. Say if the neighborhood located in NewYork, then put it into a NewYork bucket.
- When all map tasks completed, which means all neighborhoods have been put into a corresponding City Bucket. All buckets are showed in left side, different color indicates different city.
- These buckets are shuffle data!
- Then, reduce tasks begin, each Reduce task is responsible for one city, it read city bucket data from where multiple map tasks wrote. while reading bucket data, it also start to sort those data at meantime.
- Once all bucket data read(right side), we would have records of each City in which the GDP of each neighborhood is sorted.
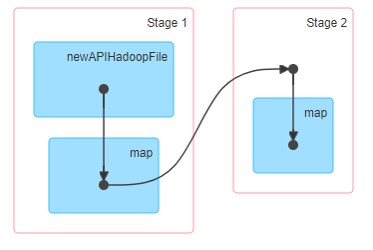
so, in spark UI, when one job requires shuffling, it always being divicded into two stages. One map stage and one reduce stage. Shown as below.
How to estimate how much data will be shuffled?
Summarize here, shuffling is a precedure for spark executors either in same physical node or in different physical nodes to exchange intermedia data generated by map tasks and required by reduce tasks. Map tasks wrote data down, then reduce tasks retrieve data for later on processing. So the data size of shuffle data is related to what result expects.
Assume the result is a ranking, which means we have an unsorted records of neighborhood with its GDP, and output should be a sorted records of neighborhood with its GDP. Then shuffle data should be records with compression or serialization.
While if the result is a sum of total GDP of one city, and input is an unsorted records of neighborhood with its GDP, then shuffle data is a list of sum of each neighborhood’s GDP.
For spark UI, how much data is shuffled will be tracked. Written as shuffle write at map stage.
If you want to do a prediction, we can calculate this way, let’s say we wrote dataset as 256MB block in HDFS, and there is total 100G data. Then we will have 100GB/256MB = 400 maps. And each map reads 256MB data. These 256MB data will then be put into different city buckets with serialization. So we can see shuffle write data is also around 256MB but a little large than 256MB due to the overhead of serialization.
Then, when we do reduce, reduce tasks read its corresponding city records from all map tasks. So the total shuffle read data size should be the size of records of one city.
What does spark spilling do?
Spilling is another reason of spark writing and reading data from disk. And the reason it happens is that memory can’t be always enough.
- When doing shuffle, we didn’t write each records to disk everytime, we will write resords to its corresponding city bucket in memory firstly and when memory hit some pre-defined throttle, this memory buffer then flushes into disk.
- Besides doing shuffle, there is one operation called External Sorter inside spark, it does a TimSort(insertion sort + merge sort) to the city buckets, since insertion data requires big memory chunk, when memory is not sufficient, it spills data to disk and clean current memory for a new round of insertion sort. Then it does merge sort to merge spilled data and remaining in memory data to get a sorted resords result.

How to estimate how much data will be spilled?
It depends on how much memory JVM can use. Spark set a start point of 5M memorythrottle to try spill in-memory insertion sort data to disk. While when 5MB reaches, and spark noticed there is way more memory it can use, the memorythrottle goes up.
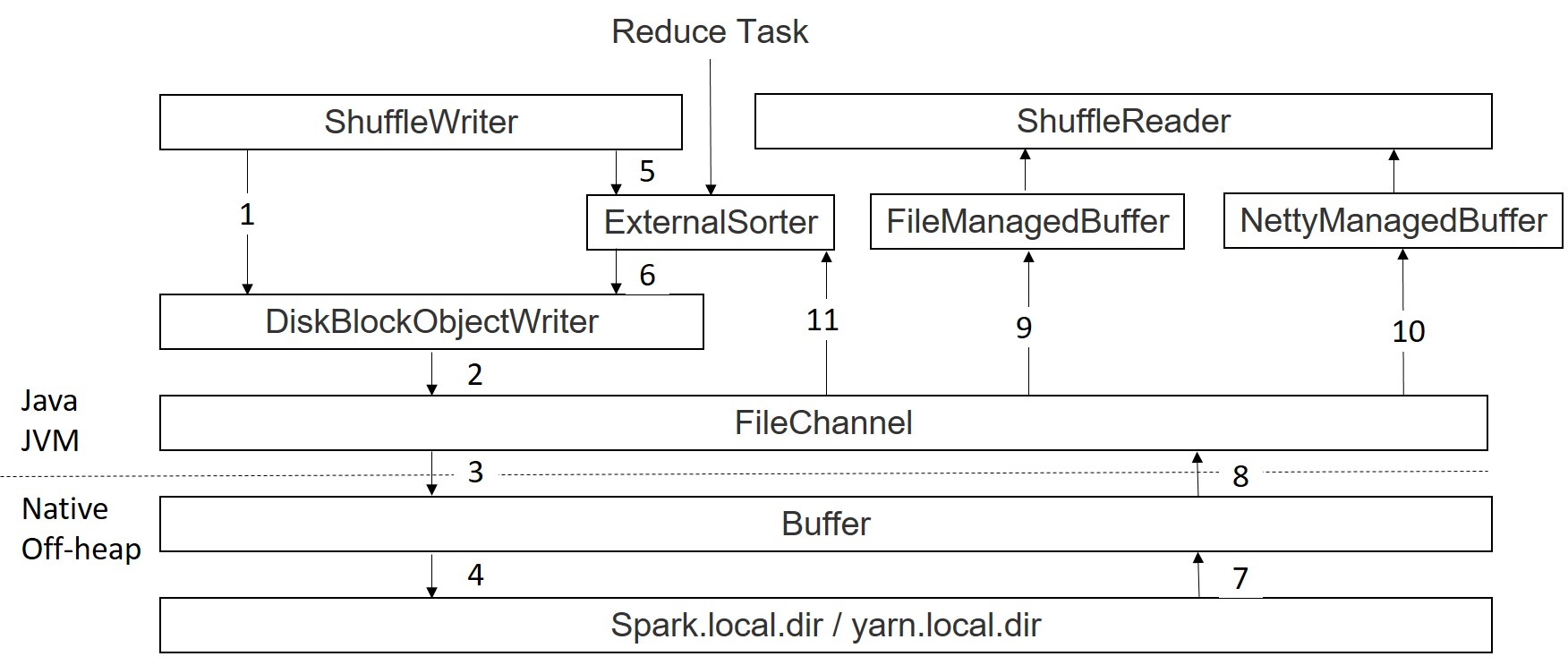
Spark Shuffle DataFlow Detail(codes go through)
After all these explaination, let’s check below dataflow diagram drawed by me, I believe it should be very easy to guess what these module works for.
No matter it is shuffle write or external spill, current spark will reply on DiskBlockObkectWriter to hold data in a kyro serialized buffer stream and flush to File when hitting throttle.
when doing data read from file, shuffle read treats differently to same node read and internode read. Same node read data will be fetched as a FileSegmentManagedBuffer and remote read will be fetched as a NettyManagedBuffer.
For sort spilled data read, spark will firstly return an iterator to the sorted RDD, and read operation is defined in the interator.hasNext() function, so data is read lazily.