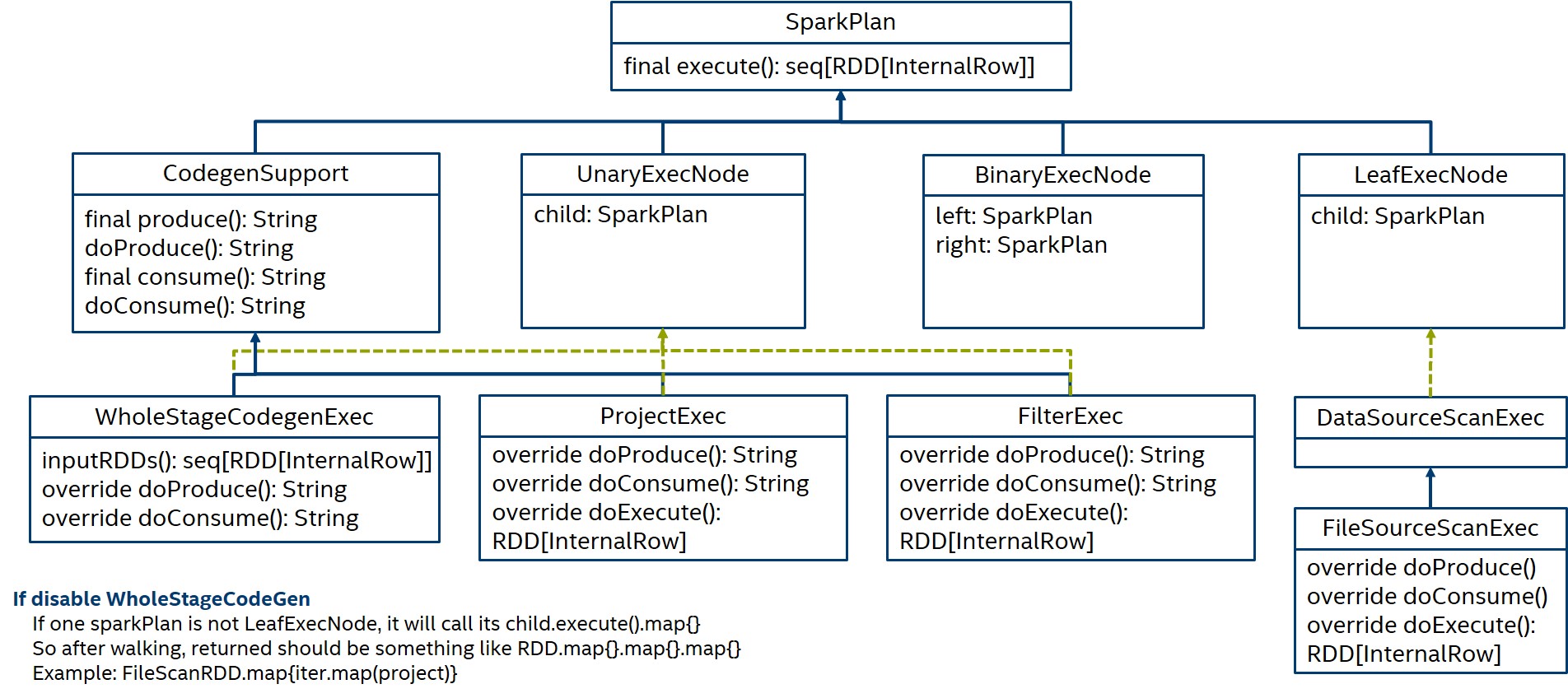
The idea of WholeStageCodeGen is an optimization to spark, as we know, spark exec flow is based on an Iterator chains of sparkplans. Before WholeStageCodeGen, when there is two spark plan in the same stage, we should see the process as something like RDD.map{sparkplan1_exec_lambda}.map{sparkplan2_exec_lambda}
And when we have WholeStageCodeGen, two sparkPlan can be processed inside one map. Above process will be optimized as RDD.map{wholestagecodegen_exec_lambda}, this wholestagecodegen_exec_lambda is a generated glue code from sparkplan1 and sparkplan2.
So, to implement this idea, spark designed a new sparkplan – “WholeStageCodeGenExec”, then use this sparkplan to trigger a tranverse among real sparkplan to create the glue code.
Before wholestagecodegen, doExecute() of each sparlplans will be called to provide the lambda for iterator. And when wholestagecodegen is enabled, for those sparkplan who support wholestagecodegen, their doProduce and doConsume functions will be called to generate a single piece of lambda.
doProduce is the function to produce input data, so only sparkplan as a leaf execnode should override and implement its own doProduce, and other sparkplans who are not leaf actually call their child’s doProduce.
doConsume is the function to consume the input data, for example, filter sparkplan provides filter code in its doConsume function.
And by calling the leaf’s doProduce and all doConsumes function of its child, wholestagecodegen then generates the glued lambda code block.
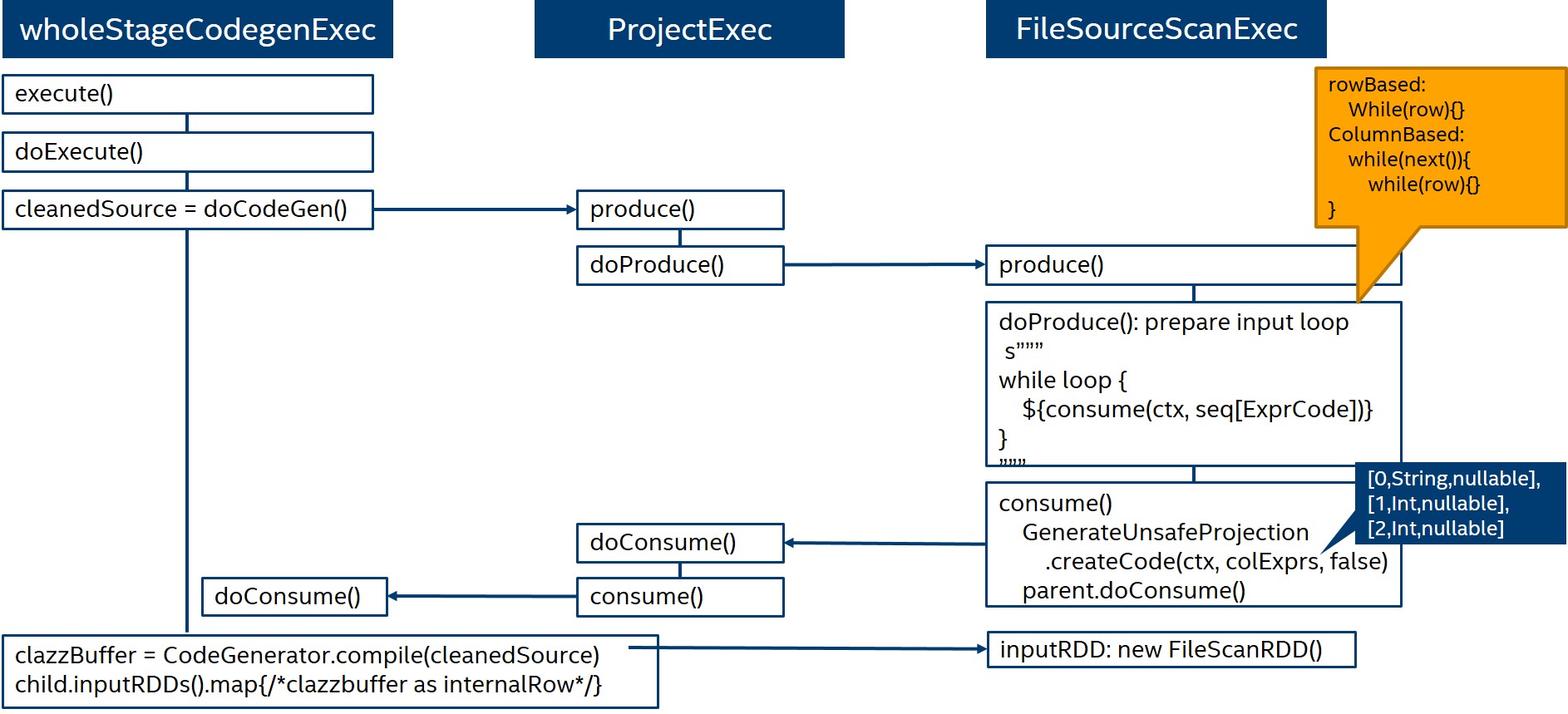
Take below graphs for a visualize example.